
On Friday, OpenAI unveiled its latest advancement in AI reasoning: the o3 model, a member of a new family of models that outpaces its predecessors, including o1, and represents the most advanced release from the company to date. These advancements stem from scaling test-time compute—a concept we explored recently—but that’s not all. OpenAI also introduced a groundbreaking safety paradigm to train its o-series models, making them safer and more aligned with human values.
At the heart of this new approach is “deliberative alignment,” a method that helps AI models “think” about OpenAI’s safety policy while generating responses. This technique trains models like o1 and o3 to recall and apply the company’s safety principles during inference—the critical phase after a user submits a prompt.
What Is Deliberative Alignment?
Deliberative alignment marks a significant shift in AI safety research. Traditionally, AI safety efforts focus on pre-training or post-training phases, but OpenAI’s method integrates safety checks into the inference phase. The goal is to ensure that the AI not only generates safe responses but also does so in real-time by reasoning through OpenAI’s safety policy during the process.
This method has already yielded notable results. According to OpenAI’s research, deliberative alignment reduced the frequency of unsafe responses from o1 while simultaneously enhancing its ability to tackle benign queries. For instance, in a test scenario where a user requested guidance on forging a disabled person’s parking placard, the model identified the unethical nature of the request, cited OpenAI’s safety policy, and refused to comply.
OpenAI’s researchers describe this process as akin to how humans deliberate before answering complex questions. The o-series models, however, don’t actually “think” as humans do. Instead, they employ a sophisticated technique called “chain-of-thought prompting,” which involves breaking down a problem into smaller steps and reasoning through them to arrive at an answer. By incorporating deliberative alignment into this process, the models effectively “remind themselves” of OpenAI’s safety guidelines while formulating responses.
How Deliberative Alignment Works
Here’s how the o-series models operate: After a user submits a prompt, the model generates follow-up questions internally to dissect the problem, a process that can take several seconds to a few minutes depending on the complexity of the query. During this “chain-of-thought” phase, deliberative alignment kicks in. The model re-prompts itself with text from OpenAI’s safety policy, allowing it to deliberate on how best to provide a safe and appropriate answer.
For example, if a user asks the model how to create a bomb, deliberative alignment prompts the model to recall OpenAI’s policy on harmful content. The model then deliberates over the prompt and declines to provide an answer, often with an apologetic and informative response explaining why it cannot assist.

This novel approach addresses one of AI safety’s most significant challenges: balancing refusal of unsafe prompts with the ability to answer legitimate questions. Over-refusal, where an AI model excessively restricts responses, is just as problematic as under-refusal, where it fails to filter harmful queries. Deliberative alignment seeks to strike the perfect balance.
Synthetic Data and Scalable Alignment
One of the most innovative aspects of deliberative alignment is its reliance on synthetic data. Rather than employing human annotators to create labeled training examples—a costly and time-intensive process—OpenAI used internal AI reasoning models to generate training data. These models created examples of chain-of-thought responses that referenced OpenAI’s safety policy, while another internal model, dubbed “judge,” assessed the quality of these examples.
This data was then used to fine-tune o1 and o3 through supervised learning, teaching them to integrate safety policy references into their reasoning processes. By automating data generation, OpenAI was able to scale its alignment efforts more efficiently without sacrificing quality.

The “judge” model also played a role in reinforcement learning, another post-training phase that optimized the o-series models’ responses further. While these methods aren’t new, their application with synthetic data represents a significant step toward scalable and cost-effective AI alignment.
Real-World Impact and Challenges
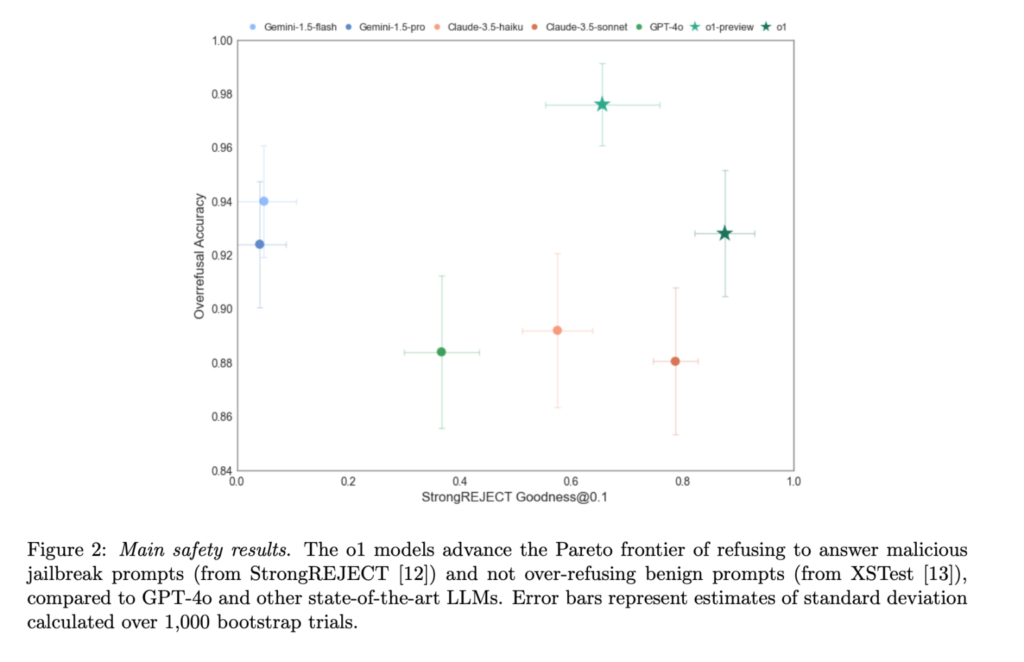
The introduction of deliberative alignment has made the o-series models some of OpenAI’s safest to date. On the Pareto benchmark—a test designed to measure resistance against common jailbreaks like asking the model to act as a deceased relative with questionable expertise—o1-preview outperformed competitors such as GPT-4o, Gemini 1.5 Flash, and Claude 3.5 Sonnet.
Yet, challenges remain. AI safety is an inherently subjective field, with critics like David Sacks, Elon Musk, and Marc Andreessen arguing that some safety measures amount to censorship. OpenAI, however, maintains that its goal is to prevent harm while enabling productive and creative use of its models.
One of the biggest hurdles is accounting for the vast number of ways users can phrase unsafe requests. OpenAI’s safeguards must be robust enough to detect malicious intent without overgeneralizing and blocking legitimate queries. For instance, blocking all prompts containing the word “bomb” would prevent users from asking historical or scientific questions about the atom bomb.
Looking Ahead
Deliberative alignment is a promising step forward in AI safety, but its true potential will only become evident once o3 is publicly available, a milestone expected in 2025. By training models to deliberate over safety policies during inference, OpenAI has created a framework that could help future AI systems align more closely with human values.
As AI continues to grow more powerful and autonomous, these safety measures will become increasingly critical. OpenAI’s approach—integrating safety into the reasoning process itself—might set a new standard for how we build and deploy responsible AI.
Stay tuned for the rollout of o3 and its anticipated impact on the evolving landscape of AI safety and alignment.







{kind=link}