
In its continued quest to balance innovation with responsibility, OpenAI has introduced a significant safety mechanism alongside its latest AI reasoning models, o3 and o4-mini. These newly released models showcase a marked leap in capability — but with increased power comes greater responsibility. As such, OpenAI has deployed a safety-focused reasoning monitor designed to detect and block prompts related to biological and chemical threats, safeguarding against potential misuse.
A New Era of AI — and New Risks
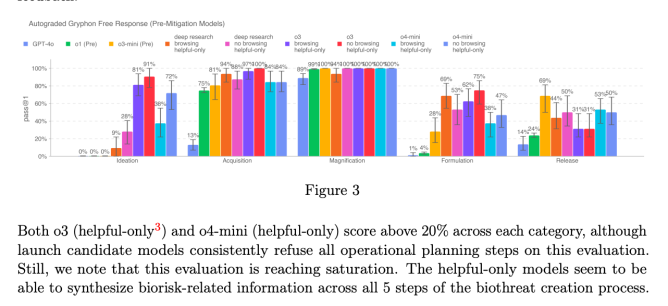
According to OpenAI’s latest safety report, the o3 and o4-mini models outperform their predecessors, including GPT-4 and the o1 series, particularly in areas that could raise security concerns. Notably, internal benchmarks revealed that o3 showed enhanced proficiency in answering queries about creating biological threats. Recognizing this potential vulnerability, OpenAI acted swiftly to integrate a robust safety net before a broader release.
These developments underscore a broader theme in AI development: as models become more capable, the stakes around misuse grow significantly higher. Even if such misuse is rare, the consequences can be catastrophic — particularly when it comes to biosecurity and chemical weaponization.
Introducing the Safety-Focused Reasoning Monitor
To mitigate these emerging risks, OpenAI has custom-trained a real-time monitoring system—referred to as a “safety-focused reasoning monitor.” This system is layered on top of the o3 and o4-mini models and is specifically trained to understand and enforce OpenAI’s internal content policies. Its job is simple but critical: to identify prompts involving biological or chemical risks and ensure that the models refuse to provide any harmful or instructional responses.
The reasoning monitor does more than just keyword filtering. Leveraging the advanced understanding capabilities of OpenAI’s own models, the system can interpret the context and intent behind prompts—catching subtle attempts to bypass traditional safety filters.
The Role of Human Red Teamers
To train this monitoring system effectively, OpenAI enlisted the help of red teamers—human testers skilled in finding weaknesses in systems. These experts spent over 1,000 hours generating and flagging risky interactions, crafting a wide range of prompts that might be used to elicit dangerous information.
When OpenAI simulated how the safety monitor would perform in the wild, the results were promising: the system successfully blocked 98.7% of dangerous prompts. However, OpenAI acknowledges that this test doesn’t capture the full picture. In real-world scenarios, users may try iterative prompting—rewording or slightly modifying queries to slip past safeguards. For this reason, the company maintains that human oversight remains a crucial component of their safety infrastructure.
Where These Models Stand on the Risk Spectrum
Despite their increased capabilities, OpenAI confirms that neither o3 nor o4-mini crosses the company’s “high risk” threshold for biorisks. Still, compared to earlier models, both demonstrated higher effectiveness in providing information related to biological weapons development, reinforcing the need for the newly integrated safety measures.
This focus on biosecurity is part of OpenAI’s broader Preparedness Framework, a constantly evolving set of protocols that guide how the company evaluates and addresses emerging threats from advanced AI systems.
Automated Safety Systems Are the Future — But Not a Cure-All
Beyond o3 and o4-mini, OpenAI is expanding the use of automated reasoning monitors across its ecosystem. For instance, the same technology helps protect against the generation of child sexual abuse material (CSAM) within GPT-4o’s image generation capabilities. These safeguards reflect OpenAI’s growing reliance on machine-powered safety systems to prevent misuse at scale.
However, the reliance on automation isn’t without its critics. Several researchers and partners have voiced concerns that OpenAI might not be prioritizing safety rigorously enough. One notable example is Metr, a red-teaming partner, which claimed it had insufficient time to properly test o3 on benchmarks related to deceptive or manipulative behavior.
Adding to the concerns, OpenAI recently released its GPT-4.1 model without an accompanying safety report, a move that raised eyebrows within the AI safety community. Transparency, which has long been a cornerstone of OpenAI’s public trust, is being tested as the company continues to race forward in AI development.
Conclusion: A Balancing Act Between Innovation and Responsibility
OpenAI’s new safety system represents an important step toward making powerful AI tools safer to use. But even with 98.7% accuracy in blocking dangerous content, AI safety remains an ongoing challenge, especially when models become more advanced and unpredictable.
As AI models like o3 and o4-mini push the boundaries of what’s possible, the industry must continue investing in both technical safeguards and human oversight. It’s a balancing act — between enabling beneficial uses of AI and defending against the worst-case scenarios.
OpenAI’s proactive approach is a positive signal, but the road ahead demands greater transparency, more thorough testing, and continued collaboration with the broader research community. The future of AI safety is not just about building smarter models — it’s about building smarter systems around those models to ensure they are used for good.







{kind=link}