
Every Sunday, NPR host Will Shortz—renowned crossword editor of The New York Times—presents a segment that challenges listeners with clever and thought-provoking brainteasers. Known as the Sunday Puzzle, this long-running tradition attracts thousands of puzzle enthusiasts who attempt to crack its tricky wordplay and lateral-thinking challenges.
Now, researchers have found an unexpected use for these beloved puzzles: evaluating the reasoning capabilities of artificial intelligence (AI) models.
A Fresh Approach to AI Benchmarking
A team of researchers from Wellesley College, Oberlin College, the University of Texas at Austin, Northeastern University, and the AI startup Cursor have repurposed NPR’s Sunday Puzzle riddles into an AI benchmark. Their goal? To assess how well reasoning models—like OpenAI’s o1—solve problems that require insight, pattern recognition, and logical deduction, rather than simple memorization or factual recall.
“We wanted to develop a benchmark with problems that humans can understand with only general knowledge,” said Arjun Guha, a computer science undergraduate at Northeastern and co-author of the study. Unlike many existing AI tests that focus on high-level math or specialized knowledge, the Sunday Puzzle benchmark is designed to evaluate problem-solving skills that are relevant to everyday reasoning.
The Problem with Traditional AI Benchmarks
The AI industry currently faces a challenge: many of the benchmarks used to measure AI performance are becoming obsolete or irrelevant. Models have rapidly surpassed human experts in tasks like passing PhD-level exams and acing standardized tests. However, these tests don’t necessarily reflect how AI performs in real-world problem-solving scenarios that the average user encounters.
This is where the Sunday Puzzle proves valuable. Unlike conventional benchmarks, these puzzles:
- Don’t require specialized knowledge – The solutions rely on logic, wordplay, and pattern recognition rather than technical expertise.
- Can’t be solved through rote memorization – AI models can’t simply retrieve an answer from their training data; they have to think through each problem.
- Continuously evolve – With new puzzles released weekly, researchers can ensure a steady supply of fresh, unseen challenges.
How AI Models Stack Up Against the Sunday Puzzle
The benchmark dataset consists of approximately 600 riddles sourced from past Sunday Puzzle episodes. On these challenges, reasoning models like OpenAI’s o1 and DeepSeek’s R1 outperform standard AI models. Unlike traditional models that often rush to an answer, reasoning models take a more deliberate approach—thoroughly fact-checking their responses and considering multiple possibilities before committing to a solution.
However, these reasoning models also exhibit some unusual and surprisingly human-like behaviors. One notable example: DeepSeek’s R1 occasionally “gives up” when it encounters a difficult puzzle, responding with the phrase “I give up” before providing a random (incorrect) answer. It’s an eerily relatable moment, mirroring the frustration that real-life puzzle solvers experience.

Other peculiar behaviors include:
- Retracting and revising answers – Models sometimes generate a wrong response, immediately recognize the mistake, and attempt to refine their solution—often unsuccessfully.
- Getting stuck in a loop – Some models enter endless cycles of analysis, struggling to settle on a final answer.
- Overthinking correct answers – Occasionally, a model will arrive at the right solution immediately, but then second-guess itself and overcomplicate its reasoning process.
According to Guha, one of the most amusing observations was that on particularly tough problems, DeepSeek’s R1 even expressed “frustration.” “It was funny to see how a model emulates what a human might say,” he said. “It remains to be seen how frustration in reasoning affects the quality of model results.”
The Best AI Problem Solver—For Now
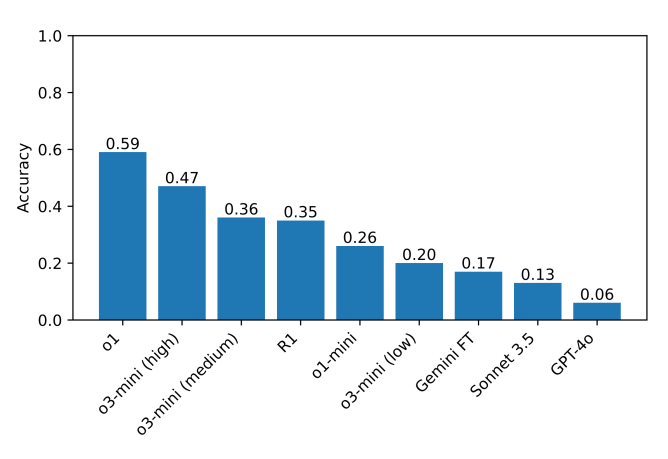
Among the models tested, OpenAI’s o1 performed the best, achieving a score of 59%. It was followed by OpenAI’s newer o3-mini (scoring 47% when set to high reasoning effort), while DeepSeek’s R1 trailed behind at 35%.
The research team isn’t stopping here. They plan to continue expanding their benchmark to include additional reasoning models, refining their understanding of where AI succeeds—and where it struggles. The ultimate aim is to design benchmarks that more accurately reflect human-like reasoning abilities.
“You don’t need a PhD to be good at reasoning,” Guha pointed out. “So it should be possible to create reasoning benchmarks that don’t require PhD-level knowledge. A benchmark with broader accessibility allows a wider range of researchers to analyze the results, which could lead to better AI solutions in the future.”
The Bigger Picture: Making AI More Human-Like
As AI becomes increasingly integrated into everyday life, understanding its reasoning abilities is more critical than ever. Benchmarks like the Sunday Puzzle test provide valuable insights into how well AI models can think through problems, not just retrieve information.
By tracking AI’s progress on this unconventional test, researchers hope to fine-tune reasoning models so they can better assist with real-world decision-making—whether that’s solving tricky riddles, debugging code, or helping users navigate complex problems in their daily lives.
Ultimately, the goal isn’t just to make AI smarter—it’s to make AI think more like us.







{kind=link}